
Google est récemment revenu sur sa façon d’analyser et d’indexer le JavaScript. Il l’analyse en deux phases : une première phase “exploration” (crawling) et quelques jours après une seconde phase qui va interpréter complètement le JavaScript. Cependant, Google rencontre quelques problèmes avec cette approche…
Les éléments canoniques passent à la trappe
Avec cette indexation en deux phases, la seconde vague d’indexation ne vérifie pas les éléments canoniques ou métadonnées. Ainsi, cela peut affecter l’indexation et le positionnement.
Cela concerne par exemple un site construit à partir d’un modèle de page unique alors toutes les URLS partagent la même base de modèle de ressources. Ces dernières sont alors remplies avec du contenu via AJAX ou des requêtes de recherche.
Et si c’est le cas, est-ce que la partie serveur initiale inclue une version de la page ayant l’URL canonique ? Parce que si vous comptez fournir cela uniquement à la partie client alors Google va complètement passer à côté.
De plus, si l’utilisateur requiert une URL qui n’existe pas et que vous essayez de lui envoyer une page 404 Google va également louper cela.
Ce ne sont pas des problèmes mineurs mais bien majeurs. Métadonnées, codes canoniques, et HTTPs sont tous des éléments clés pour la compréhension du contenu de votre page web par les moteurs de recherche.
Le “Dynamic rendering” comme solution
Ainsi, Google recommande aux webmasters d’utiliser la technique du “dynamic rendering”. Il s’agit d’envoyer le contenu “normal” côté client aux utilisateurs et d’envoyer le contenu complet côté serveur pour les moteurs de recherche qui en ont besoin.
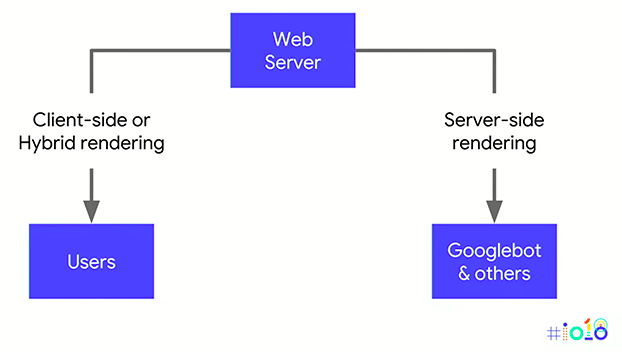
Pour ceux qui se demandent si cela sera considéré comme du Cloaking (« dissimulation »), non ce ne le sera pas le cas si cela est effectué correctement. En effet, utilisateurs et Googlebot verront le même contenu, ce sera simplement présenté différemment pour que le Googlebot puisse l’indexer correctement dès le premier passage, donc pas de triche !